In today’s data-driven world, the ability to efficiently extract, transform, and load (ETL) data is a crucial skill for any data professional. ETL processes enable organizations to turn raw data into meaningful insights, empowering informed decision-making. As I delve deeper into the realm of ETL, I’ve found PySpark to be an invaluable tool. In this blog post, I’ll share my journey into exploring ETL with PySpark, highlighting its capabilities, advantages, and some practical use cases.
What is ETL?
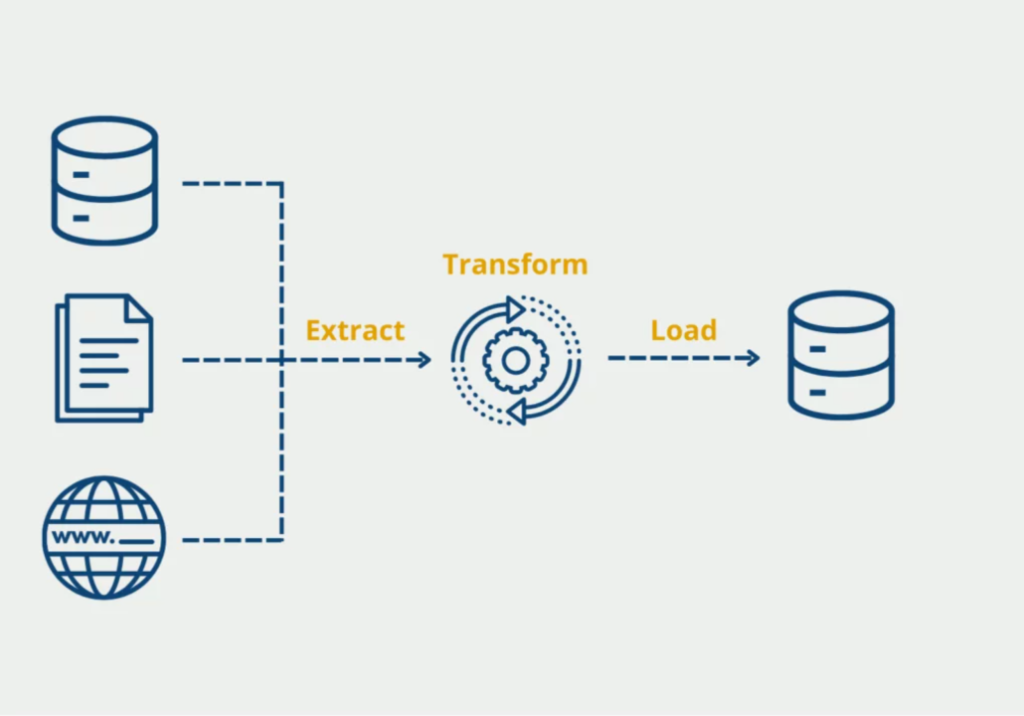
ETL stands for Extract, Transform, and Load. It is a data integration process that involves:
- Extracting data from various sources such as databases, APIs, and flat files.
- Transforming the extracted data into a format suitable for analysis by cleaning, aggregating, and enriching it.
- Loading the transformed data into a target system, such as a data warehouse or a data lake.
ETL processes are fundamental to data warehousing and analytics. They ensure that data is accurate, consistent, and ready for analysis, enabling organizations to derive actionable insights.
Why PySpark?
PySpark is the Python API for Apache Spark, an open-source distributed computing system. Spark is renowned for its ability to process large datasets quickly and efficiently. By leveraging PySpark, data professionals can harness the power of Spark while writing code in Python, a language known for its simplicity and readability.
Advantages of PySpark for ETL:
- Scalability: PySpark can handle large datasets across a distributed cluster, making it ideal for big data ETL tasks.
- Speed: Spark’s in-memory computing capabilities significantly speed up data processing compared to traditional ETL tools.
- Flexibility: PySpark supports a wide range of data sources and formats, including JSON, CSV, Parquet, and more.
- Integration: PySpark integrates seamlessly with other big data tools and frameworks, such as Hadoop, Hive, and Kafka.
Getting Started with PySpark for ETL
Let’s walk through a simple ETL process using PySpark. We’ll extract data from a CSV file, transform it by filtering and aggregating, and load the transformed data into a new CSV file.
Step 1: Setting Up PySpark
First, you’ll need to install PySpark. You can do this using pip:
bashCopy codepip install pyspark
Next, set up a Spark session:
pythonCopy codefrom pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("ETL with PySpark") \
.getOrCreate()
Step 2: Extracting Data
Let’s assume we have a CSV file named sales_data.csv containing sales information. We’ll load this data into a PySpark DataFrame:
pythonCopy code# Define the schema
from pyspark.sql.types import StructType, StructField, IntegerType, StringType, DoubleType
schema = StructType([
StructField("order_id", IntegerType(), True),
StructField("product", StringType(), True),
StructField("quantity", IntegerType(), True),
StructField("price", DoubleType(), True),
StructField("date", StringType(), True)
])
# Load the CSV file into a DataFrame
sales_data = spark.read.csv("sales_data.csv", header=True, schema=schema)
Step 3: Transforming Data
In the transformation step, we’ll filter the data to include only orders with a quantity greater than 10 and calculate the total sales for each product:
pythonCopy code# Filter orders with quantity greater than 10
filtered_data = sales_data.filter(sales_data.quantity > 10)
# Calculate total sales for each product
from pyspark.sql.functions import col, sum
transformed_data = filtered_data.groupBy("product").agg(sum(col("quantity") * col("price")).alias("total_sales"))
Step 4: Loading Data
Finally, we’ll save the transformed data into a new CSV file:
pythonCopy code# Save the transformed data to a new CSV file
transformed_data.write.csv("transformed_sales_data.csv", header=True)
Real-World Use Cases of PySpark ETL
PySpark is used in various industries for ETL processes. Here are a few examples:
- E-commerce: Extracting and transforming sales data to gain insights into customer purchasing behavior.
- Finance: Aggregating and analyzing transaction data to detect fraud and optimize trading strategies.
- Healthcare: Processing patient data to identify trends and improve treatment outcomes.
- Telecommunications: Analyzing network data to enhance service quality and customer satisfaction.
Conclusion
ETL is a critical component of data integration and analytics. PySpark, with its scalability, speed, and flexibility, is an excellent choice for building robust ETL pipelines. By mastering PySpark, data professionals can efficiently process large datasets and derive valuable insights, driving data-driven decision-making.
As I continue to explore ETL with PySpark, I’m excited about the possibilities it offers. Stay tuned for more updates and insights as I delve deeper into the world of data processing and analytics.
